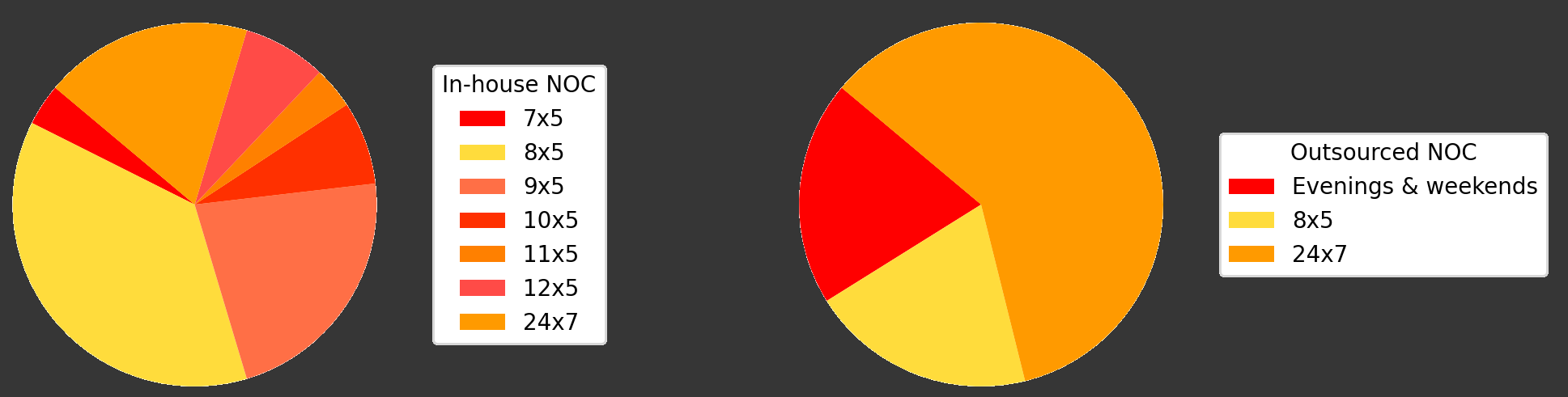
Vi har framgångsrikt implementerat NOC-tjänster för många kunder, och erbjuder support dygnet runt, inklusive helger och kvällar. Vår beprövade metod säkerställer att dina IT-system ständigt övervakas och hanteras effektivt. Vår erfarenhet understryker vikten av 24/7 NOC-support och Remote Monitoring Management (RMM) för att snabbt åtgärda problem och bibehålla smidiga operationer.