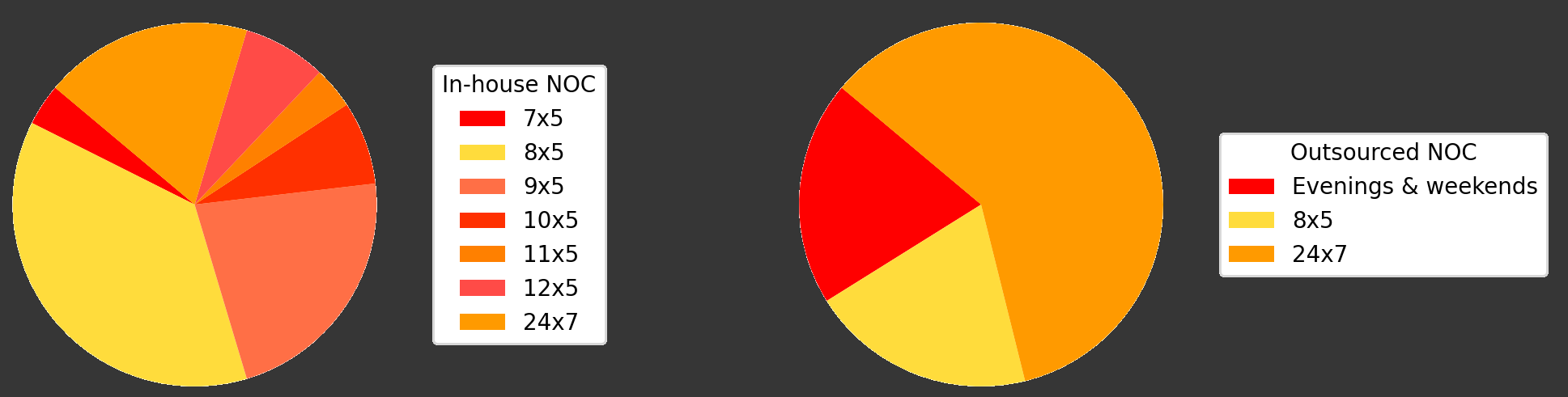
Мы успешно внедрили услуги NOC для множества клиентов, обеспечивая круглосуточную поддержку, включая выходные и вечера. Наш проверенный подход гарантирует, что ваши ИТ-системы постоянно мониторятся и эффективно управляются. Наш опыт подтверждает важность круглосуточной поддержки NOC и удаленного мониторинга (RMM), что позволяет быстро решать проблемы и поддерживать бесперебойную работу.