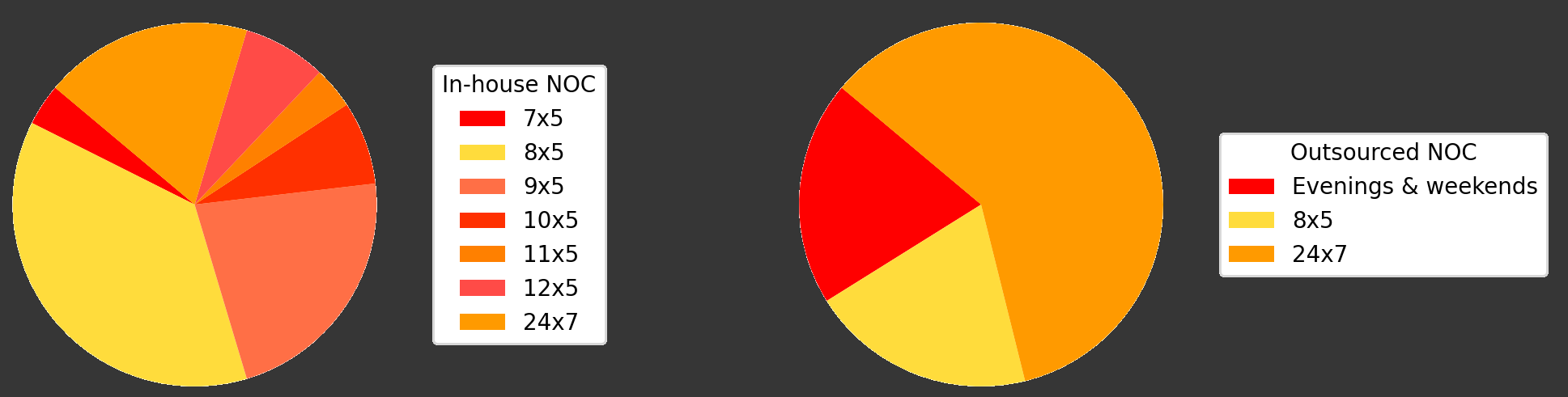
Vi har med succes implementeret NOC-tjenester for mange kunder, der giver support døgnet rundt, inklusive weekender og aftener. Vores afprøvede tilgang sikrer, at dine IT-systemer konstant overvåges og styres effektivt. Vores erfaring understreger vigtigheden af 24/7 NOC-support og Remote Monitoring Management (RMM) for hurtigt at løse problemer og opretholde en stabil drift.